Blogs & News
Work on Larger Data with the New Data Table Sampling Feature
Aridhia are now launching the ability for users to work on large datasets within the DRE with the introduction of the new Data Sampling feature.
Datasets in the data science world are becoming increasingly larger in size and here at Aridhia we are continuously upgrading our platform to accommodate for these demands. To that end, we are introducing our newest feature: Data Sampling.
This is a feature that allows users to open a large dataset using the built-in Data Table Editor (DTE) inside a workspace. Instead of having to deal with the reduction in speed and increased memory demand that can come with working with large datasets, the DTE will pull out a random sample of rows from the dataset, providing a more manageable view to look at and work with. When the Data Table Editor is in Sample Mode, it will aim to display 250,000 cells, so the number of rows presented will depend on how many columns your dataset has.
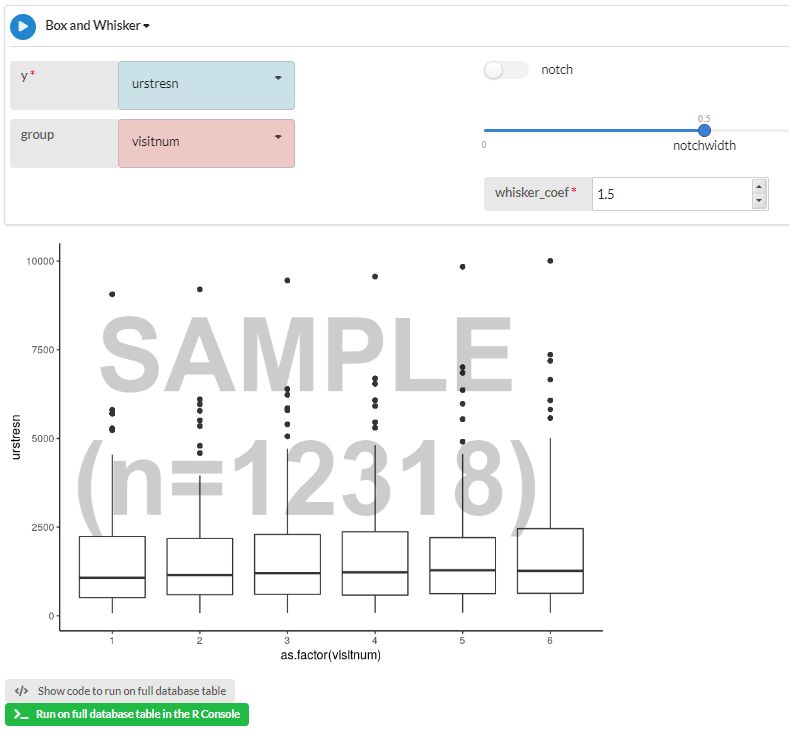
A Box and Whisker analysis of a data sample
After the sample has been presented, you can run any of our included Data Table Analytics (DTA) Modules across it (you can find more information on these in the Data Table Analytics Knowledge Base article). Doing so, maintains the fast processing times you are used to while allowing you to make any adjustments needed to get the analysis and plot to the state that you want it. When you are happy with it, it will give you the option to run it against the entire dataset in the R Console where, depending on how many rows your dataset has, it can take a little bit longer. But since the analysis has already been run on the sample, you should already have made all the necessary adjustments, so you only need to run the analysis on the full dataset once. While waiting on the outcome of the analysis, you are free to use all the other features of your workspace, including opening the DTE on another dataset.
During the development of this feature many different datasets were tested, including datasets with 12 million rows or 600 columns or over 1 GB range in size, demonstrating the types of size of dataset that can now be easily handled by the DTE. To give the users of this feature the best performance speeds, it is only available for datasets that have been converted to a database table inside the workspace database and not for CSV files. There is an easy-to-use tool inside the workspace that will help you convert your large CSV files into database tables so they can be used in Sample mode.
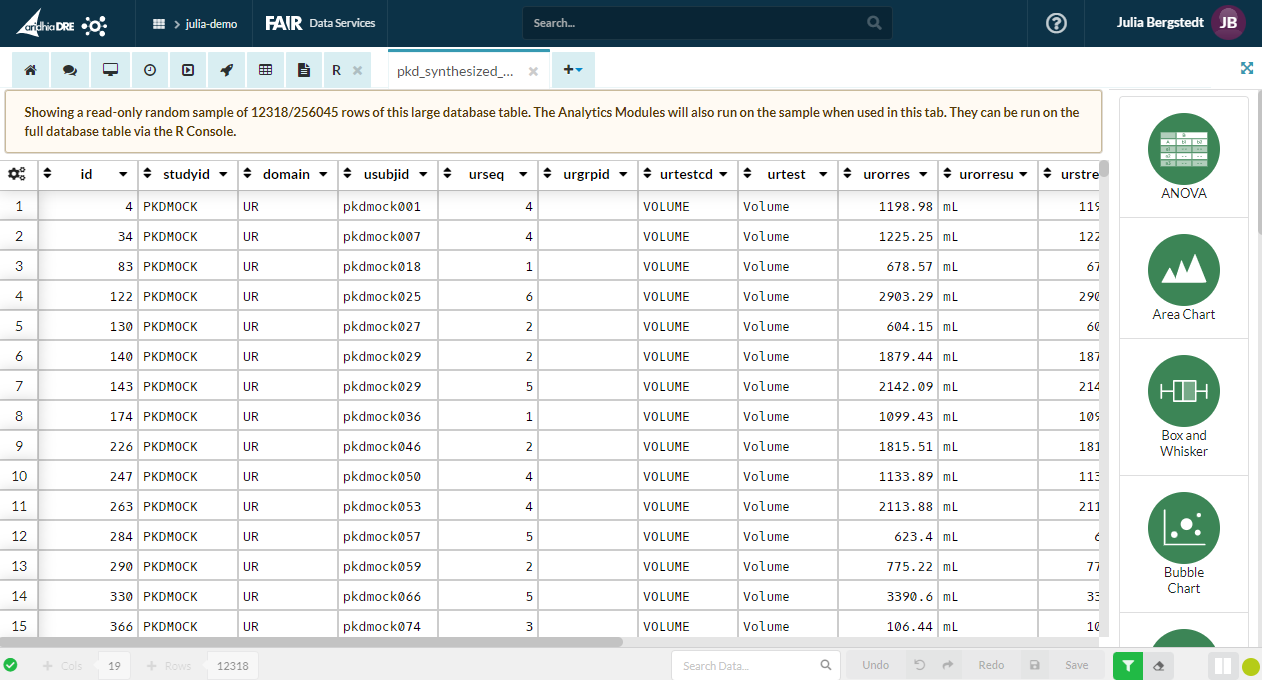
A view of the Data Table Editor
The DTA Modules are a good tool to use to get a sense of the shape of a dataset when you are first exploring it. They are also very helpful for users that are less comfortable writing their own R code, since they provide the R code that was used to generate each analysis. This code can then be added to an R script or run in the R console where you can make any modifications needed to make the plot appear exactly as you want it. That is why we put a lot of effort into removing the previous size limitations for the DTA Modules by introducing this sample feature. Now all users, even if their datasets used to be too large, can use the Analytics Modules to get valuable information about their data, either as a final analysis step, or as a stepping-stone on the path to more advanced analysis with the other tools available in the workspace.
If you want to learn more about this feature, and how you can use it in a workspace, you can read more about it in this article.