Blogs & News
Accessibility: A blueprint of how to make data accessible
In a previous blog, we discussed the ‘F’, or Findability, of the FAIR data principles. Even with an understanding of datasets via clear, concise and exhaustive metadata, researchers still often face the difficult task of obtaining access to the dataset.
Accessibility of a dataset does not imply that data should be instantly available for use but “as open as possible and as closed as necessary” [European Commission]. Typically, there are three methods to obtain access to data:
- Open: data is readably available. Many researchers are willing to provide access to their datasets on an unrestricted basis, however this in the minority.
- License-based: a license is required to access the data under strict conditions that may require a fee.
- Request-based: data is available to users upon request and submission of their purpose, objectives and intended usage.
While in healthcare settings the latter approach is typically employed, obtaining access to data can often be difficult, with complex request processes and turnaround times of request decisions. Data governance policies and restrictions imposed by data owners rightly try to strike a balance between satisfying ethical and regulatory requirements, and data confidentiality, particularly when data contains personal information. This can however restrict the ability of researchers collating necessary datasets to analyse and innovate to help improve patient outcomes. See our blog article discussing data this balancing act in relation to sharing data here.

FAIR and Accessibility
The Accessibility (or ‘A’) of FAIR defines a dataset to be accessible when:
- A1. (meta)data are retrievable by their identifier using a standardised communications protocol.
- A1.1 the protocol is open, free, and universally implementable.
- A1.2 the protocol allows for an authentication and authorisation procedure, where necessary.
- A2. metadata are accessible, even when the data are no longer available.
With open, free and standardised protocols such as HTTP(s) to retrieve data via identifiers (as defined in principle F1), the process to access a dataset is primarily defined through authentication and authorisation workflows.
Note that these principles do not outline how these workflows are implemented, what features of a dataset are released or how much of the dataset is released. For example, this may be a synthetic or de-identified version of the dataset, or a limited subset of data defined by the data owner. Private datasets could adhere to the Accessible principles if a process exists to access this data.
Authentication
Authentication can be added to protect the visibility and security of data where users must register and login to see and access data. Open identity management standards such as OAuth and developed solutions such as Azure Active Directory, Okta, Auth0, etc, can be used to protect and control access to data and associated metadata. The addition of authentication to obtain or request access to data is entirely optional, however a number of tiered levels of per-dataset visibility and access exist:
- Private: metadata and data are private to the data owner and assigned authenticated users with appropriate permissions (e.g. data stewards).
- Internal: metadata is available to view for authenticated users, where access to data is either available immediately or upon request.
- Public: metadata is available to view for non-authenticated and authenticated users, where access to data is either available immediately or upon request when the user authenticates.
- Open: as discussed above where both metadata and data are available immediately, however in some circumstances an automatically approved access request may be necessary for governance and audit purposes.
A data platform providing access to data will ideally implement all authentication tiers allowing data owners to select the level of dataset visibility and access on a per-dataset basis.
Authorisation
Authorisation is an ambiguous term when applied to procedures of requesting and obtaining access to data. Below are some important components of a potential authorisation procedure, or Data Access Request (DAR) in relation to a data aggregator platform, e.g. those collating and providing access to datasets from various communities and data owners:
- User verification
- Data access request form
- Acceptance of dataset requirements
- Data access request workflows
- Request review and decision
User Verification
To reduce the risk of data misuse, leakage or breaches of any data usage agreements in place, requesting users should be verified before sharing any data – primarily to confirm their identity but also as is common, whether they are from a valid institution who would likely be interested in using the requested data.
Three such approaches that are often combined to reduce the aforementioned risks are:
- Registration verification: applicable for private, internal and public authentication tiers where users are (at least part) verified during the registration process to the system. Email verification and Multi-factor Authentication (MFA) do provide some level of identity verification however additional information can be captured such as institution details, job title, area of expertise, etc. to understand the broader user persona requesting data. Online identifies, such as ORCID, or online profiles can also assist data owners with verification. Contractual agreements such as data usage agreements as well as general terms and conditions can optionally be accepted upfront at registration if agreements apply across all residual datasets in the data aggregator platform.
- Manual user verification: supplied user details, either at the time of registration or request, are used to contact the user to verify the details they have provided. This may add additional time to an access request if verification cannot happen soon after request.
- Automated user verification: automated identify verification systems are well established in highly regulated environments such as banking, which can be tightly integrated with other transaction monitoring systems to help verify identity. In contrast, typically healthcare data platforms allowing data to be requested, must take user details at face value and work independently to verify identity. Depending on the data to be shared, more relaxed verification rules can be employed to automatically verify users based on the details provided and speed up the process.
Data Access Request Form
Equally important to user verification is understanding why a user requires access to a dataset. As a minimum, data owners want to understand:
- Why does the user require the data?
- What are the user’s objectives and can they be validated?
- Is the request associated with a research project? If so, what are the details of the project? Ideally projects can be traced to a valid and funded research project.
- What safeguards exist to satisfy any data agreement(s) conditions?
The data access request form captures this information. Commonly these forms are static and are applied to all datasets within a data aggregator platform, however with the greater volumes and types of data being generated in healthcare settings, forms should be both extensible and relevant to the dataset being requested, e.g. a dataset with strict release conditions will require more information to be provided than those with lesser restrictions. By doing so, requesting users need not supply unnecessary information that a data owner does not require as part of the decision review process.
Processes should exist to allow users to request access to multiple datasets concurrently by adopting smart form capabilities to streamline the user’s request experience but still capture the information required by the data owner. Similarly, an access request need not apply to the entire dataset. A data selection extension can be added to the request form giving requesting users the ability to select tables or define cohorts of interest to request access to. Understanding how the data will be used can be defined by introducing a Data Usage Ontology (DUO) to semantically tag datasets with usage restrictions that requesting users must specify and adhere to upon access (e.g. “for non-profit use only”, “for Alzheimer’s research”, etc.)
Request forms should also be machine-readable (e.g. JSON) to assist with sending request information to external sources where the request review process occurs elsewhere. A good example of this is work underway as part of the ADDI AD Workbench allowing requests to be completed by users in FAIR Data Services but requests are sent to the data owner to review via an API integration with their request review system. A request decision (approval or denial) is issued by a callback to FAIR Data Services that then informs the requesting user.
Acceptance of Dataset Agreements
A dataset will usually have one or more associated agreements that need to be entered into before data is released to a user. Regardless of the agreement in place, data owners must clearly outline the conditions of access to assist requesting users whether requesting access is worthwhile. This may involve exposing a Data Usage Agreement (DUA) defining, but not limited to:
- The dataset to be shared.
- Those who may use the dataset.
- An agreement between parties that the data must be appropriately safeguarded.
- How findings derived from the dataset can be used, e.g. in publications.
Governance measures should be developed to audit datasets, capture all outcomes of requests, list users who have been provided access and what and when associated agreements, were entered into. Dataset agreements and compliance is a subject that merits a detailed overview that will be covered in a future blog post.
Data Access Request Workflows
Research organisations and data owners will employ different workflows on how a data access request is processed and ultimately approved or denied. This can depend on an organisations internal processes, interactions with users, the content of the request or the dataset in question, to name a few. Workflows should be assigned on a per-dataset basis that ideally can be created and deployed by data owners in a self-service manner.
Detailed below are five types of data access request that should be supported by a data aggregator platform:
- Internal: the access request and data owner (or committee) review and approve or deny the request all within the same platform.
- External: the access request occurs within the data platform, however the request is handed to a third-party via API where review and decision occurs. A call-back is made to the data platform to update the request decision and inform the requesting user.
- Multi-stage: the access request must pass through multiple stages of approval, for example, two or more data owners.
- Business-rule: a workflow with defined automation rules, e.g. auto-approval of ‘public’ datasets or users that already agreed to the DUA.
- Mixed: a mixture of either some or all of the above.
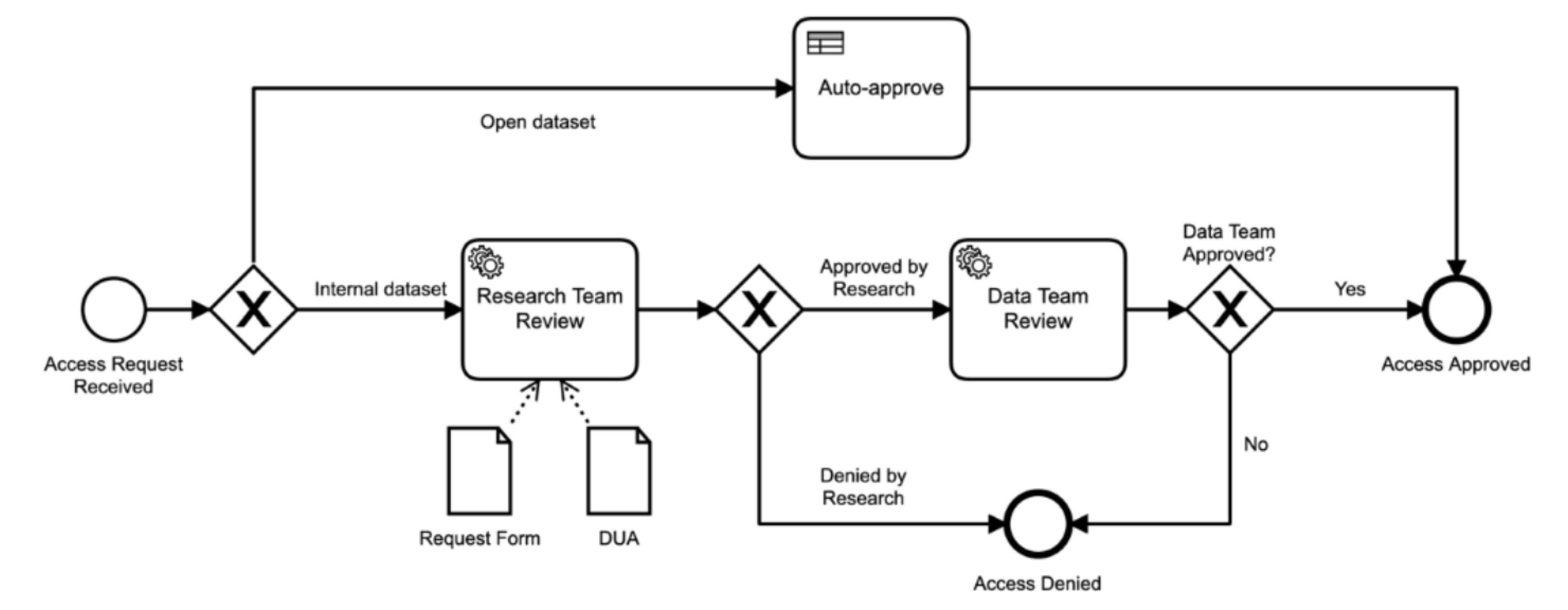
This example workflow shown (represented as a Business Process Model and Notation chart), depicts a common access request workflow that includes multiple stages and business rules. Note either review stage could be handled internally within a data aggregators platform or externally via a third-party.
In the example, an access request is received and if the dataset is an open dataset, the request can be automatically approved by the platform. Otherwise, the dataset must reviewed by both the Research and Data teams to gain approval, however request denial can occur at either of these stages. Data access request processes can be greatly sped up by integrating a feedback loop where requesting users can contact data owners and iteratively re-work their access requests, or obtain feedback when requests have been denied.
Request Review and Decision
A data owner needs to have at least all the information provided by the requesting user to help make a judgement on approving or denying an access request. However additional information and features should be made available to increase both the correctness and timeliness of the decision. For example:
- To differentiate between internal and external request workflows, the source platform where the request was initiated.
- The current status of the user verification process, e.g. unverified or verified.
- The date when the user was last verified. This may trigger re-verification at regular intervals with verification provenance recorded.
- A list of the user’s requests and reasons for decisions.
- If the workflow is multi-stage, the ability to pass on any relevant information to subsequent reviewers.
- The ability to contact requesting users to discuss the request, e.g. if subtle changes are required to approve.
Upon reviewer decision, requesting users should be informed of both the decision and reason, particularly when a request is denied. Access should then be granted to the user in secure manner compliant with any agreements, e.g. securely transferring data to a Digital/Trusted Research Environment.
Summary
The requirements listed above provide one blueprint on how to improve existing data access request processes. Without continued improvements in this area, lengthy and complex data access processes will soon become the primary bottleneck of healthcare data innovation. Automation, customised, and streamlined access request processes will be key going forward.
We will explore some of the concepts above in more detail in further blog posts as well as outline how FAIR Data Services can help make data accessible.