Blogs & News
To share or not to share – the ever-present tension in biomedical research
The COVID-19 pandemic has brought the need for effective data sharing and collaboration into sharp focus. Sometimes it takes a crisis to catalyse an acceleration in behaviour.
Broadly speaking, most scientific teams acknowledge the benefits of contributing data for health and biomedical research; learning and experience should be shared, data standards allow accurate comparison and aggregation increases the statistical power of all studies. Trusted collaboration around data improves study outcomes and benefits citizens, funders, and the scientific community in general. Much more can be done to reduce the friction surrounding the sharing of data without compromising data governance and appropriate use.
 Notwithstanding the developments made in legal frameworks such as GDPR, open technical standards and open source tooling, there are deeply embedded cultural and behavioural barriers regarding the sharing of data as most researchers will readily attest. The urgency of the pandemic is bringing governance frameworks, technical standards, and open data approaches together with an urgency that, frankly, is long overdue. At Aridhia, we’ve been wrestling (for a long, long time) with the technology approaches to balancing the seemingly opposing demands of open science and information governance.
Notwithstanding the developments made in legal frameworks such as GDPR, open technical standards and open source tooling, there are deeply embedded cultural and behavioural barriers regarding the sharing of data as most researchers will readily attest. The urgency of the pandemic is bringing governance frameworks, technical standards, and open data approaches together with an urgency that, frankly, is long overdue. At Aridhia, we’ve been wrestling (for a long, long time) with the technology approaches to balancing the seemingly opposing demands of open science and information governance.
The cultural element of this balancing act is the more difficult one to resolve and I mention it merely to call it out: it’s not something that the technical community can do much to resolve. Funders need to move from making broad policies of sharing data within their funding conditions to a level of specificity as to what that actually means in practice. In this area the technical community can make a meaningful contribution to what that data sharing consists of (versus being a loaded phrase) and provide the services to facilitate. Looking slightly wider than the biomedical research world, hundreds of thousands of software people globally use Github daily to host and share code for re-use and redeposition, choosing whether to share openly or within private groups as a pre-cursor to wider publication. Variants of this model should be embraced and specified by funders to accelerate data sharing for biomedical research in general, helping a move to open science and moving the dial on scientific reproducibility.
At Aridhia, our contribution is to help build technical solutions that address the needs of the user community (the demand) while satisfying the governance needs of the data controllers (the supply). That’s a balancing act, but it is addressed by being specific about what’s being requested and specific about what you intend to do with the data. The worry from the data controller is a loss of control and the frustration for the researcher is fishing in the dark for what’s available with little clarity on whether it’s possible to secure access and indeed, even worthwhile pursuing. We’re working to improve both sides of the equation, and as a data processor, we’re neutral in this game and focused on providing a workflow that’s built for ease of use, efficiency, and transparency.
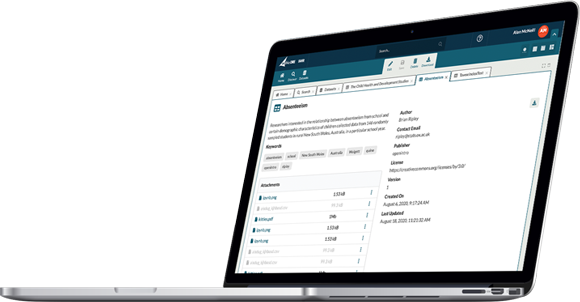 We’re continuing to invest in growing the portfolio of FAIR Data Services to allow the community to discover what data is available through syndication with willing data participants, to encourage the open publication of metadata, to help researchers understand what data is potentially available and to have data access request services that deal with the diversity of requests from the user community. We want to template, configure and publish the workflow for discovery, request, selection, and approval to make each request specific and aligned to the science question being pursued. There’s still a persistent and pervasive sense that somehow everything of interest in a particular field (Cancer, COVID-19, Alzheimer’s) is sitting in some complete repository somewhere or that somebody wants to build and own that repository. The truth for now and probably forever is the complete opposite; people have useful data, but it’s rarely complete (from the eyes of someone else) and is rarely sufficiently powered for the big clinical research questions and to be truly useful it needs to be accessible under the right conditions. Having good data curated locally, metadata syndicated and a published method for sharing ought to be the norm and all of that is perfectly feasible through a portfolio of modern cloud services. The next post will outline an approach we’ve piloted for data controllers to self-select their preferred method for sharing that explicitly aligns governance requirements with data sharing approaches, one of which is federation.
We’re continuing to invest in growing the portfolio of FAIR Data Services to allow the community to discover what data is available through syndication with willing data participants, to encourage the open publication of metadata, to help researchers understand what data is potentially available and to have data access request services that deal with the diversity of requests from the user community. We want to template, configure and publish the workflow for discovery, request, selection, and approval to make each request specific and aligned to the science question being pursued. There’s still a persistent and pervasive sense that somehow everything of interest in a particular field (Cancer, COVID-19, Alzheimer’s) is sitting in some complete repository somewhere or that somebody wants to build and own that repository. The truth for now and probably forever is the complete opposite; people have useful data, but it’s rarely complete (from the eyes of someone else) and is rarely sufficiently powered for the big clinical research questions and to be truly useful it needs to be accessible under the right conditions. Having good data curated locally, metadata syndicated and a published method for sharing ought to be the norm and all of that is perfectly feasible through a portfolio of modern cloud services. The next post will outline an approach we’ve piloted for data controllers to self-select their preferred method for sharing that explicitly aligns governance requirements with data sharing approaches, one of which is federation.
 We’ve recently piloted an approach to federated data sharing building on the work of the Global Alliance for Genomics and recently published this as an open source data sharing framework. The results from our pilot activity are encouraging and we’re now building out a network based on this as part of the International Data Alliance for COVID-19 and looking for new groups to join and contribute.
We’ve recently piloted an approach to federated data sharing building on the work of the Global Alliance for Genomics and recently published this as an open source data sharing framework. The results from our pilot activity are encouraging and we’re now building out a network based on this as part of the International Data Alliance for COVID-19 and looking for new groups to join and contribute.
Whether addressing the pressing needs of COVID-19 or the desire to build common data resources for particular conditions, the choice of how data is shared, used and attributed needs to become more transparent and arguably become as important as the study itself. More to follow…