Responsible and secure use of generative AI in a Trusted Research Environment
The hidden data‑exposure risks behind “AI‑enabled” TREs
AI is changing how researchers work. LLMs can speed up literature reviews, help write code, harmonise messy datasets, and support clinical decision-making. TRE vendors have noticed, and most are now adding AI features to their platforms.
But when you type a prompt into an AI assistant inside your Trusted Research Environment, where does that data go? As a data owner, how do you ensure that Generative AI technologies are being used appropriately and responsibly?
External API calls break the model
The whole point of a Trusted Research Environment is that sensitive data stays inside the secure boundary. Airlocks control what goes in and out, network isolation keeps the environment separated and output checking ensures nothing identifiable leaves. The SATRE specification sets out these requirements, and frameworks like ISO 27001 audit against them.
However, when a platform calls out to OpenAI, Google, Anthropic, or any other cloud-hosted LLM, every prompt gets transmitted to infrastructure outside your TRE. Your research queries leave the secure environment. The context and data derivatives get processed on someone else’s servers. Those prompts might be logged, stored, or used for model training. You have limited visibility into what happens to them. LLM providers may also make tool calls to other services and you have no control over this. This further expands to the boundaries of where data may go.
Contractual assurances don’t change the basic fact that your data left the TRE.
The consequences of irresponsible GenAI use
When GenAI is used carelessly, small mistakes can trigger major security, ethical, and operational consequences. Here are just a few examples of security incidents and data breaches related to LLM API services which should give pause for thought with how these technologies are used alongside a TRE:
Corporate Data Leaks via Employee Use
Samsung (April 2023)
Samsung employees accidentally leaked confidential semiconductor source code, chip testing sequences, and internal meeting notes by pasting them into ChatGPT. Three separate incidents occurred within 20 days. Samsung subsequently banned ChatGPT use company-wide.
- Bloomberg: Samsung Bans Generative AI Use by Staff After ChatGPT Data Leak
- Dark Reading: Samsung Engineers Feed Sensitive Data to ChatGPT
Research by Cyberhaven found that 3.1% of employees at client companies had submitted confidential data into ChatGPT, with companies of 100,000+ employees potentially sharing secrets hundreds of times per week. .
GitHub Copilot Security Issues
API Keys and Secrets Leakage (2021–2025)
GitHub Copilot has been shown to reproduce real, valid API keys and credentials from its training data. Researchers have extracted functional secrets through prompt engineering.
Microsoft Copilot “Zombie Data” Vulnerability (2025)
Security researchers found that Microsoft Copilot could access code from over 20,000 GitHub repositories that were previously public but later made private, exposing 300+ API keys/tokens and affecting 16,290 organisations including Microsoft, Google, Intel, and PayPal.
CamoLeak – Private Repository Exfiltration (June 2025)
A critical vulnerability (CVSS 9.6) in GitHub Copilot Chat allowed attackers to silently exfiltrate AWS keys, security tokens, and even undisclosed zero-day vulnerability descriptions from private repositories.
OpenAI Platform Breaches
ChatGPT Data Leak (March 2023)
A Redis library bug exposed chat history titles and payment information (names, emails, addresses, last four digits of credit cards) for 1.2% of ChatGPT Plus subscribers during a nine-hour window.
Credential Theft at Scale (2023)
Group-IB discovered 101,134 devices with stolen ChatGPT credentials between June 2022 and May 2023, primarily via Raccoon, Vidar, and RedLine malware. Over 225,000 OpenAI credentials were later found for sale on the dark web.
Mixpanel Analytics Breach (November 2025)
A third-party analytics provider breach exposed names, email addresses, and location data for OpenAI API users.
Most Trusted Research Environments haven’t caught up
Irresponsible GenAI use risks data leaks, fabricated outputs, weak governance, and TRE breaches, with external LLM APIs bypassing safeguards and exposing sensitive information.
Are TREs ready for the risks of generative AI?
The risks of using these technologies irresponsibly are very real. In 2023, Samsung engineers pasted confidential source code into ChatGPT to help debug it — data that’s now stored on OpenAI’s servers. Researchers at Cyberhaven found that over 3% of employees at client companies had submitted confidential data to ChatGPT, with some organisations sharing sensitive information hundreds of times per week. Lawyers have been sanctioned for submitting AI-generated court filings containing fabricated case citations. This is what happens when powerful tools get used without proper governance and control.
LLMs should be assumed to contain a copy of their training data which is reproducible given the right prompt as noted in this submission to UK Parliament in 2024. In a TRE context, this data includes patient data, research IP, commercially sensitive methodologies and without appropriate responsible control, all of it could, quite accidentally, end up in prompts sent to external services and could then be reverse engineered. With this in mind, in the AI in the NHS: rewards, risks, and reality article from digital health, December 2025, Professor Christina Pagel, director of University College London’s clinical operational research unit states, correctly, that real progress requires “secure, ring-fenced models within hospitals, trained on local datasets under strict governance.”
However, there are few hard guidelines or specific standards in this area. The closest that TREs have to a standard is the SATRE specification which focuses on traditional data access. While it doesn’t address the use of generative AI technologies directly, Pillar 2, does address areas relevant to this:
2.1.9 “You must mitigate and record any risks introduced by the use in your TRE of software that requires telemetry to function.”
2.2.9 “Your TRE must control and manage all of its network infrastructure in order to protect information in systems and applications.”
2.2.11 “Your TRE must block outbound connections to the internet by default.”
2.1.9 is particularly important. Risk assessment must be conducted by the TRE administrator if they are to enable access to AI providers.
A December 2025 Cloud Security Alliance report found only about a quarter of organisations have comprehensive AI security governance. The OWASP Top 10 for LLM Applications 2025 lists the key risks such as prompt injection, data disclosure, system prompt leakage. Most current TRE security models have not been designed to handle these, however, researchers will increasingly demand access to this technology. The temptation may be to take a short cut, and provide API access to AI providers. However, as discussed,when LLMs are accessed via external APIs, traditional airlock controls don’t apply. The data leaves at the network layer, invisible to the governance processes meant to protect it. This technology is undoubtedly useful for research but the does your TRE’s governance framework cover how they’re being used?
Using offline LLMs in a TRE – A case study
Learn how offline LLM’s can work securely from within a Trusted Research Environment in a case study using breast cancer data.
Questions to ask
To be sure that GenAI technology is used responsibly in any TRE, your information governance team needs clear answers to the following:
Where does inference happen?
Is the LLM running inside the TRE, or does it call out to external services?
What data leaves the Trusted Research Environment?
Even “anonymised” prompts can contain identifiable information or reveal sensitive research directions.
Which models, and who controls them?
Open-source models can be self-hosted. Proprietary models usually mean external API calls.
What gets logged externally?
Does the AI provider keep your prompts? For how long? What do they use them for?
How does this affect compliance?
Can the vendor show that AI integration doesn’t compromise their accreditation?
What auditing is available?
What records of prompts and inferences are available from the platform used.
Do you retain prompts?
Are long term histories retained, how secure are they and who can access them? How are those prompts used?
If a vendor can’t answer these, there is a gap in their security architecture and it must be assumed that GenAI technology cannot be used responsibly.
Is your research environment ready for AI?
Assess your organisation’s readiness to govern AI use on sensitive data. Ten questions. Three minutes. A clear picture of where you stand and what to address.
How we’ve approached this at Aridhia
We’ve been working on this problem at Aridhia for a while now. The result is AIRA, our AI Research Assistant framework. The principle behind it is simple: data owners and administrators should control how AI gets used, with visibility and audit trails for every interaction. This ensures the responsible use of AI within a controlled and secure environment.
Offline Inference
AIRA runs a proprietary scheduling framework for model execution, all on workspace infrastructure. Nothing leaves your dedicated secure cloud environment, be it prompts, context, or research queries and there’s no telemetry going to external services. Every inference job gets logged in the DRE’s audit system. Administrators have complete control over which models are available and who can access them.
Governed API Passthrough
Sometimes external AI services make sense. Code completion in embedded Workspace IDEs such as VS Code, Jupyter or Marimo is a good example where the risk profile is different from research data analysis, and the productivity benefits are real.
AIRA supports this, but with controls:
- Administrators decide whether external API access is allowed. It’s off by default.
- Every API call gets logged, including prompts and responses, so there’s full visibility into what’s being sent out.
- Configuration is granular. Admins can permit external APIs for specific tools while keeping research analysis on offline models.
Data owners make this choice deliberately, with audit trails, rather than it happening as a hidden default.
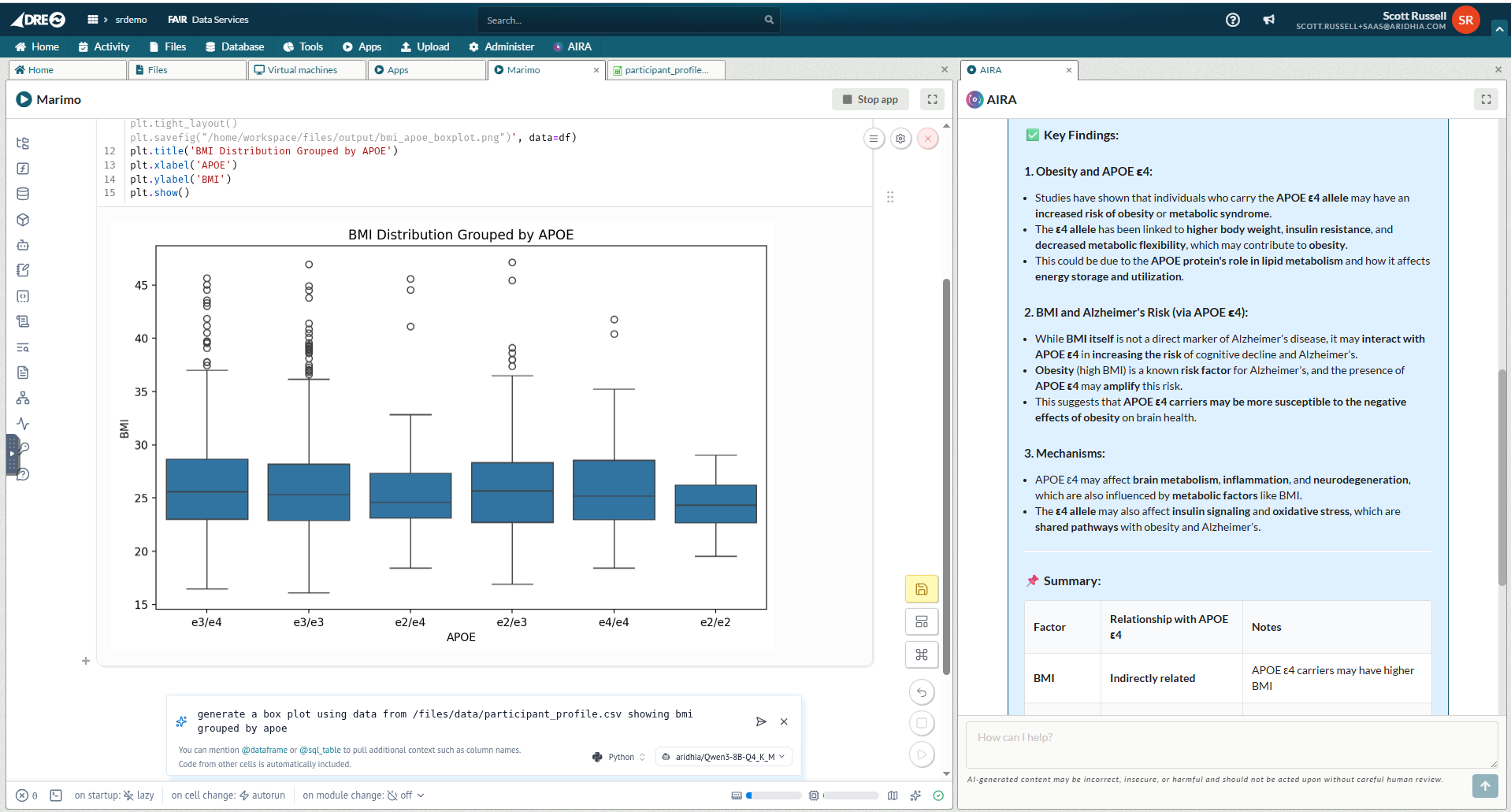
Compliance
GDPR, HIPAA, NHS DSPT all require control over patient data. External API calls raise questions such as: where exactly was the data processed? Which jurisdiction applies? Who can see the logs?
With Offline LLMs you avoid these entirely by ensuring data residency is guaranteed and demonstrable to auditors.
Information Sovereignty
There’s a question that often gets overlooked: can you explain how an AI-generated answer was produced? Can you reproduce it?
External AI services are black boxes and model versions change without warning sometimes with unpredictable results. The ChatGPT 5 release is a great example of a new model release flipping everyone’s tables.
System prompts and configurations are hidden and you can’t guarantee the same query will give the same result next week, let alone when you need to defend your methodology to a regulator.
For research, this matters:
- Reproducibility: If your research uses AI models, you need to be able to reproduce your results. Which model? Which version? Which parameters?
- Audit trails: “We asked an external AI service” doesn’t satisfy regulators or ethics committees. You need provenance.
- Peer review: Your methods need to be documented. That’s hard when key components are controlled by a third party.
AIRA’s offline architecture addresses this by giving administrators control over which model versions are deployed and how they are made available to workspaces. The full chain from prompt to response is captured in audit logs.
Aira – AI Research Assistant Framework
Our secure, offline LLM framework embedded in the Aridhia DRE, engineered to give healthcare researchers unparalleled control over sensitive data, uncompromising performance, and seamless integration.
Picking the responsible approach
AIRA lets organisations use AI responsibly by keeping sensitive work offline, governing API use, and ensuring full audit trails so TRE security and control are never compromised.
We’re not saying don’t use AI or don’t use external APIs, far from it. We encourage the use of this groundbreaking technology responsibly.
With AIRA, organisations can pick the right approach for each situation:
- Sensitive research analysis runs on offline models where nothing leaves the boundary.
- Developer productivity tools can use external APIs if you want, with full audit trails.
- Different workspaces can have different policies based on data sensitivity.
Data owners know where sensitive data goes and platform owners have evidence for regulators. Admins and Principal Investigators have audit trails for all AI interactions.
Summary
AI has real potential to accelerate healthcare research, but that potential shouldn’t come at the cost of the security principles that make TREs trustworthy. The combination of the Aridhia DRE Workspaces for secure data collaboration and AIRA for responsible AI use provides researchers with a secure framework for AI assistance while keeping control with the data owners and administrators. External API access can then be made available where it makes sense, but as a governed and traceable choice.
If you want to know more about how AIRA works within the Aridhia DRE, get in touch.
AI and the Aridhia DRE
Learn more about how the Aridhia DRE utilises AI and why we think it’s the most secure option for health research:
Artificial Intelligence Opportunities to Guide Precision Dosing Strategies
Precision dosing uses patient data and AI‑enabled platforms like the Aridhia DRE to individualise therapy and support future MIPD advances.
Federated Node AI: A Prototype for Prompt-Based Data Interaction
Federated Node AI tests with SLMs for prompt‑based federated analysis showing FN can relay prompts, run tasks & return results while exploring future workflows
AI Meets FAIR: Enabling Semantic Search in Trusted Research Environments
This blog explains what vector search is, details the changes we have made to integrate it with FAIR, and how hub owners can enable and optimise this service.